- Published in: IEEE Conference on Decision and Control (CDC) 2019
- Authors: Jeong Woo Kim, Hyungbo Shim, and Insoon Yang
- Abstract: Because reinforcement learning (RL) may cause issues in stability and safety when directly applied to physical systems, a simulator is often used to learn a control policy. However, the control performance may be easily deteriorated in a real plant due to the discrepancy between the simulator and the plant. In this paper, we propose an idea to enhance the robustness of such RL-based controllers by utilizing the disturbance observer (DOB). This method compensates for the mismatch between the plant and simulator, and rejects disturbance to maintain the nominal performance while guaranteeing robust stability. Furthermore, the proposed approach can be applied to partially observable systems. We also characterize conditions under which the learned controller has a provable performance bound when connected to the physical system.
Introduction and motivation
Over the past decade, reinforcement learning (RL) has achieved a lot of successful results such as game and autonomous vehicle. However, training on real physical systems has several difficulties such as long training time and instability due to an exploratory input signal. As a result, most of the RL results for physical systems are limited in simulation level.
On the other hand, unlike simulation model, a real plant is affected by real-time external disturbance and plant uncertainty or modeling error. Due to these discrepancies, such learned controller trained in simulation may not perform well but also cause instability when connected to the real plant (Fig.1).

Recently, many researches related to this Sim-to-Real issue have studied as follows:
“Sim-to-real: Learning agile locomotion for quadruped robots”
Tan. et al.
arXiv preprint arXiv:1804.10332
“Sim-to-real transfer robotic control with dynamics randomization”
Peng. et al.
arXiv preprint arXiv:1710.06537
“Learning agile and dynamic motor skills for legged robots”
Hwangbo. et al.
Science Robotics, 2019
However, they have common limitation. They focused on empirical experiment rather than theoretical analysis such as sub-optimality bound on control performance.
So, our goal is, under the plant uncertainty and the real-time external disturbance, we want to improve the robustness of such learned controller via simulator. In particular, we aim to characterize conditions under which the learned controller has a provable performance and to compute that sub-optimality bound on control performance.
Our idea is simple. We pursue Real-to-Sim, not Sim-to-Real. In other words, we want to make the uncertain real plant behave like the simulation model by implementing an additional inner-loop controller. And then, we combine them with the learned controller trained in simulation (Fig.2)

To make the real plant behave like the simulation model, the first question we have to ask ourselves is “can we compute a quantity of the difference between them?”. As shown in the following left figure, consider a real plant whose inputs are u and disturbance d, and the output is y. We want to find how much compensates for the simulation model to generate the same output y with the same input u.

$$y(s)={\color{red}{P}(s)}(u(s)+{\color{red}d(s)})\\
={{P_n}(s)}u(s)+[ -{{P_n}(s)}u(s)+{\color{black}{P}(s)}(u(s)+{\color{black}d(s)}) ]\\
={{P_n}(s)}u(s)+{{P_n}(s)}{[ -\left(1-\frac{{P}(s)}{{P_n}(s)}\right)u+\frac{{P(s)}}{{P_n}(s)}d(s) ]}\\
=:{\color{blue}{P_n}(s)}(u(s)+{d_{total}(s)})$$
Using basic algebra, we can quantify this difference as square bracket term in above third equation and we define this as “total disturbance” (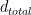
In 1983, Ohishi proposed disturbance observer or DOB shown in the figure where Q represents a low-pass filter called Q-filter. As shown in the following equations, since 

$$\hat{d}(s)=-{Q}(s)u(s)+{P_n^{-1}}(s){Q}(s)y(s)\\
={Q}(s){[(1-\frac{{P}(s)}{{P_n}(s)})u+\frac{{P(s)}}{{P_n}(s)}d(s)]}={Q}(s){d_{total}(s)}$$
Suppose that the disturbance is dominant in a low-frequency range and Q approximate to 1 in that low frequency range. Then

Training step: Design of RL-based Controller for Simulation Model
Consider a single-input single-output nonlinear simulation model whose relative degree is 

Since the simulation model has no uncertainty, 
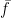
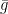

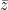
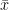
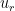
One of the biggest advantage of the DOB is that it can be combined with any pre-existing controller. In other words, you can design your controller with your favorite RL algorithm to train it for the simulation model. So, in this paper, we used a Q-learning to evaluate Q-function of the simulation model and then exploit it as shown in the slide.
$$u_r=\arg\max_{u\in{A}} {Q}({[\bar{z};\bar{x}]},u)$$
Application step: Applying the Learned Controller to Partially Observable Real Plant with DOB
As a counterpart of above simulation model, the uncertain real plant is represented as SISO nonlinear with same relative degree

The disturbance observer (DOB) can be implemented as the follows:

Since the learned controller requires the full state information, it is difficult to apply the controller only with the output of the real plant. Fortunately, DOB can estimate the state 

The overall structure of the proposed idea is shown.

Now we want to confirm that is there any performance degradation due to adopting the DOB and if so, we want to compute the sub-optimality bound on control performance. First, define the nominal control performance for the nominal closed-loop system consists of the simulation model and the learned controller.
$${J}_{[{\bar{z}_n(0)};{\bar{x}_n(0)}]}(u_r)=\int_0^\infty e^{-\lambda t}r([{\bar{z}_n(t);\bar{x}_n(t)}],u_r(t)) dt$$
Also, define the real control performance for the real closed-loop system consists of real plant, learned controller and DOB.
$${J}_{[{\bar{z}(0)};{{x}(0)}]}({u_p})=\int_0^\infty e^{-\lambda t}r([{\bar{z}(t)};{{x}(t)}],{u_p(t)}) dt$$
Let 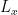
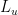




Theorem states that if the learned controller is stable for the simulation model, then the sub-optimality bound which means the performance degradation level of the real control performance with respect to nominal control performance is represented like above inequality. The constant 
In fact, the second term of the bound is generated by the difference between the nominal solution and the real solution. Since the DOB can make the difference of solution in 
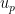
In addition, note that if the reward function does not depend on input or
Example Study
We specify the target system as a simple inverted pendulum whose goal is to make the pendulum swing up. The state is pendulum’s position and velocity and the action is input torque. Also, the reward is the negative quadratic sum of its position and velocity. Note that the system has a maximum reward of zero only when the pendulum is sustaining at the upright position.

From its dynamics, the real plant can be represented as followings:
$$\dot{x}(t)=
\begin{bmatrix}x_2(t)\\ \frac{g}{\color{red}l}\sin(x_1(t))\end{bmatrix}+
\begin{bmatrix}0\\ \frac{1}{m{\color{red}l}^2}\end{bmatrix}(u(t)+{\color{red}d(t)}),\\
y(t)=\begin{bmatrix}1&0\end{bmatrix}x(t), \qquad x(0) =\begin{bmatrix}\pi&0\end{bmatrix}^\top.$$
Note that the length of pendulum 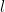



After training the controller for the simulation model, the learned controller is applied to the real plant.

The left figure shows the result of the real closed-loop system without DOB and the right figure shows the result of the real closed-loop system with DOB. The color level represents the total sum of the reward in each case. And x-axis and y-axis represent the variation of uncertain length of the pole and the amplitude of disturbance. It can be easily confirmed that there is a significant improvement in control performance by implementing the DOB.
Summary: Benefits of the proposed idea in the view of RL
By adopting the DOB, the proposed idea
- can guarantee robust stability even for the uncertain plant
- can be applied to a class of partially observable systems
- can be combined with any RL algorithm which stabilizes the simulation model
Comments are closed.