- Published in: The IEEE Control Systems Letters (L-CSS)
- Authors: Seungjoon Lee and Hyungbo Shim
- DOI: 10.1109/LCSYS.2019.2916250
- Abstract: Economic dispatch problem for a networked power system has been considered. The objective is to minimize the total generation cost while meeting the overall supply-demand balance and generation capacity. In particular, a more practical scenario has been studied by considering the power losses. A non-convex optimization problem has been formulated where the non-convexity comes from the nonlinear equality constraint representing the supply-demand balance with the power losses. It is shown that the optimization problem can be solved using convex relaxation and dual decomposition. A simple distributed algorithm is proposed to solve the optimization problem. Specifically, the proposed algorithm does not require any initialization process and hence robust to various changes in operating condition. In addition, the behavior of the proposed algorithm is analyzed when the problem is infeasible.
This work is a continued effort of CDSL to tackle the distributed optimization problem and its application to the economic dispatch problem (EDP). For our previous works, see https://post.cdsl.kr/archives/1263 or https://post.cdsl.kr/archives/615. This post only
What is the Economic Dispatch Problem?
The economic dispatch problem (a.k.a. resource allocation problem) is a fundamental problem which arises in the operation of the power network. The EDP considers a network of 

Economic dispatch problem is often formulated into an optimization problem (which we call original problem) given by

where 
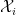
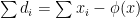
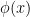
Most of the existing literature on EDP solve the problem formulated as above with 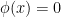
In this work, we suppose that the losses of the system
$$\phi(x) = \sum_{i=1}^N \phi_i(x_i)$$
where 

Challenge when dealing with losses
As this work consider the losses of the system, this leads to two main challenges compared with previous works.
1. Nonconvexity of the Problem
Note that the formulated optimization problem with nonlinear loss function is not a convex optimization problem. Hence, it is in general hard to solve for the optimal solution. In order to overcome this challenge, we relax the original problem into the following

where we have relaxed the nonlinear equality constraint into an inequality constraint. Therefore, the relaxed problem is now convex and can be solved efficiently (in a centralized manner).
However, it should be asked whether the optimal solution obtained from the relaxed problem is at any use. Specifically, there are no reasons to solve the relaxed problem if its results are not meaningful. For this, we make
- Monotonic cost function $$ 0 < \frac{df_i}{dx_i}, \quad \forall x_i \in \mathcal{X}_i$$
- Realistic Loss Model $$ \frac{d\phi_i}{dx_i} < 1, \quad \forall x_i \in \mathcal{X}_i$$
Both of the assumptions are easily satisfied in case of the EDP. For instance, it is typical to use a quadratic cost function given by 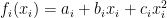
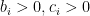
Fortunately, under the stated assumptions, it can be shown that the optimal solution obtained from the relaxed problem is in fact also optimal to the original problem. Therefore, we can instead solve
2. Constrained Dual Problem
Since the relaxed problem is convex, the relaxed problem can be formulated into the dual problem using similar techniques from this result and hence details are not discussed. In conclusion, we can obtain

Here, 



The function 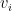
The main difference with previous results is that now the dual problem is a constrained optimization problem. The constraint 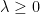

Interestingly, it can be shown that even with the new modified dual function, the dual problem is still concave and hence it is a concave, unconstrained optimization problem. Moreover, the vanilla gradient ascent algorithm can be applied to obtain the optimal solution.

Finally, it has been shown in the paper that the solution to the modified dual problem (which can be obtained via vanilla gradient ascent algorithm) is, in fact, an optimal solution to the original problem we wanted to solve.
Distributed Solution
The gradient descent algorithm proposed in
$$\dot{\lambda}_i = \frac{d\mathcal{L}_i(\hat{x}_i(\lambda_i),\lambda_i)}{d\lambda_i} + k \sum_{j \in \mathcal{N}_i} (\lambda_j – \lambda_i)$$
where 
$$\dot{\lambda} = \frac{1}{N} \sum_{i=1}^N \frac{d\mathcal{L}_i(\hat{x}_i(\lambda),\lambda)}{d\lambda}$$
which is the centralized gradient ascent algorithm (with some scaling factor). Hence, using the theory of the blended dynamics developed at CDSL, it holds that the solution of the distributed algorithm approximately converges to the optimal solution.
Further Discussions
The paper contains additional results for the proposed distributed algorithm. For instance, although the algorithm converges approximately, it is shown that the overall supply and demand balance is always satisfied exactly. Moreover, the behavior of the algorithm is also analyzed when the problem is infeasible. If you are interested, please see our paper for these results.
Comments are closed.